Jsoup介绍
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
关于Jsoup的介绍,请访问Jsoup的官网:http://jsoup.org/
关于Jsoup的jar包下载地址:http://jsoup.org/download
关于Jsoup的官网API文档查询:http://jsoup.org/apidocs/
关于Jsoup的中文使用示例:http://www.open-open.com/jsoup/
干货集中营
干货集中营是代码家大神做的一款每周一至周五中午都会分享妹子图和技术干货网站,可以通过API,获取公开数据。
大家通过开放API练习开发自己的APP集中营,现在网上流传这各式各样的APP,但是犹豫受到了接口的限制(毕竟大神都是很忙的),所以不能做出自己理想的APP。
今天就教大家使用Jsoup来获取集中营当中闲读的数据。
下面言归正传…
抓取需要的数据
首先进入闲读直接右键显示网页源码(或者F12);我们可以看到很多HTML+CSS标签;我使用的是Google Chrome浏览器;
1 2 3 4 5 6 7 8 9 10 11 12 13
| <div id="xiandu_cat"> <ul> <li><a style="border: 1px solid #747474;" href="/xiandu">科技资讯</a></li> <li><a href="/xiandu/apps">趣味软件/游戏</a></li> <li><a href="/xiandu/imrich">装备党</a></li> <li><a href="/xiandu/funny">草根新闻</a></li> <li><a href="/xiandu/android">Android</a></li> <li><a href="/xiandu/diediedie">创业新闻</a></li> <li><a href="/xiandu/thinking">独立思想</a></li> <li><a href="/xiandu/iOS">iOS</a></li> <li><a href="/xiandu/teamblog">团队博客</a></li> </ul> </div>
|
这里直接找到要抓取的数据闲读分类,之后需要分析是从什么节点开始才是一条数据;就好比数组[{},{}]一样;里面每个数据都是以什么开头的;这里分析之后可以看到是以<div id="xiandu_cat">为节点就是一组数据;<a>相当于一条数据,需要获取标签里面分类名字和分类的href;
我们所需要的东西已经找到;接下来我们去抓取出数据封装一下就可以用了;
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| List<ReadTypeBean> datas = new ArrayList<>(); try { Document doc = Jsoup.connect("http://gank.io/xiandu").get(); Elements tads = doc.select("div#xiandu_cat").select("a"); for (Element tad : tads) { ReadTypeBean bean = new ReadTypeBean(); bean.setTitle(tad.text()); bean.setUrl(tad.absUrl("href")); datas.add(bean); Log.v("Jsoup","title= "+bean.getTitle()+" url= "+bean.getUrl()); } } catch (IOException e) { subscriber.onError(e); }
|
可以看到先是通过Jsoup.connect(url).get();获取一个Document;
这样就可以通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据;
首先解析上面说的节点<div id="xiandu_cat">下面的所有<a>标签,会得到一个Elements通过for循环取出需要的数据;
text()获取标签中的文本,absUrl(“href”) 提取地址的绝对路径;
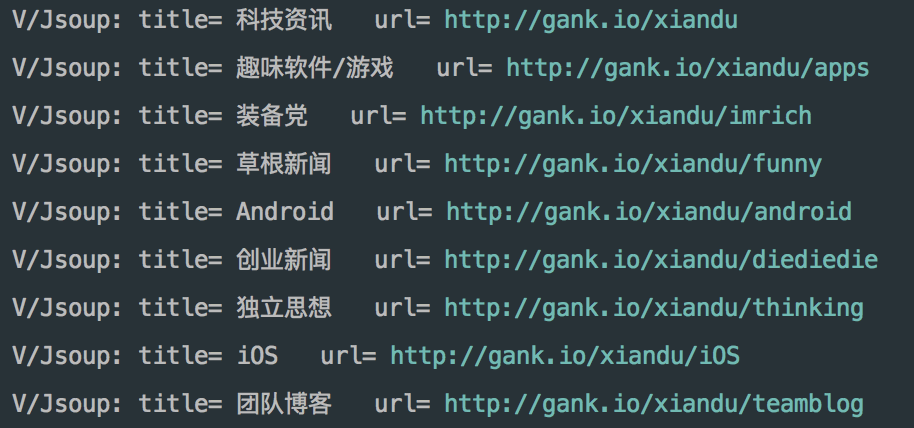
可以看到我们需要的数据已经打印出来了;
下面就是提取页面上的子分类和列表数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| <<div class="xiandu_choice"> <ul> <li> <a href="/xiandu/view/engadget"> <img src="http://ww1.sinaimg.cn/large/0066P23Wjw1f9rym3y697j30300300sj.jpg" title="Engadget 中文版" alt="" class="site-img"> </a> </li> <li> <a href="/xiandu/view/williamlong"> <img src="http://ww2.sinaimg.cn/large/0066P23Wjw1f9u8ddodymj3020020wea.jpg" title="月光博客" alt="" class="site-img"> </a> </li> </ul> </div>
|
同理找到子分类<div id="xiandu_choice">为节点的数据;和上面的的分类同样的方法获取即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| <div class="xiandu_item"> <div class="xiandu_left"> <div class="upvote"></div> <span class="xiandu_index">1:</span> <a class="site-title" href="http://www.ifanr.com/832492?utm_medium=website&utm_source=gank.io%2Fxiandu" target="_blank">在通往信用社会的路上,学会用芝麻分“薅羊毛”也是一件正经事</a> <span> <small> 16 分钟前 </small> </span> </div> <div class="xiandu_right"> <a class="site-name" href="/xiandu/view/ifanr" title="爱范儿" target="_blank"> <img src="http://ww3.sinaimg.cn/large/0066P23Wjw1f9rylijz6rj3030030gle.jpg" alt="" class="site-img"/> </a> </div> </div>
|
上面可以看到<div class="axiandu_item">为节点就是一条数据;里面有两个div节点,我们需要的详情连接和标题是在<div class="xiandu_left">层下的标签<a href>中;
我们需要的图片和类别是在<div class="xiandu_right">层下的<img src>里面;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
| ReadTypeBean readTypeBean = new ReadTypeBean(); readTypeBean.setTitle(requestContext.getType()); readTypeBean.setUrl(requestContext.getUrl()); List<ReadChildTypeBean> readChildTypeBeanList = new ArrayList<>(); List<ReadListBean> readListBeanList = new ArrayList<>(); try { Document doc = Jsoup.connect(requestContext.getUrl()).get(); Elements childs = doc.select("div.xiandu_choice").select("a"); for (Element child : childs) { ReadChildTypeBean bean = new ReadChildTypeBean(); Elements img = child.select("img"); bean.setTitle(img.attr("title")); bean.setImg(img.attr("src")); bean.setUrl(child.absUrl("href")); readChildTypeBeanList.add(bean); } Elements items = doc.select("div.xiandu_item"); for (Element item : items) { ReadListBean bean = new ReadListBean(); Elements aLeft = item.select("div.xiandu_left").select("a"); bean.setTitle(aLeft.text()); bean.setLink(aLeft.attr("href")); bean.setTime(item.select("small").text()); Elements aRight = item.select("div.xiandu_right").select("a"); bean.setSource(aRight.attr("title")); bean.setLogo(aRight.select("img").attr("src")); readListBeanList.add(bean); } Element button = doc.select("a.button").last(); readTypeBean.setPage(button.absUrl("href")); } catch (IOException e) { subscriber.onError(e); } readTypeBean.setReadListBeanList(readListBeanList); readTypeBean.setReadChildTypeBeanList(readChildTypeBeanList);
|
上面的就是获取所有分类页面的数据,可以看到在最后面还有doc.select("a.button").last();,通过分析html代码页面上有两个button类型的标签,使用last()得到最后一位button的地址就是下一页面的数据,从而实现上拉分页的效果。
封装使用
接着我们就是接收跟封装数据了,毕竟我们习惯了后台服务器返回的那种json数据;接下来写一个简易的Bean类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
| public class ReadTypeBean implements Parcelable { private String title; private String url; private String page; public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getPage() { return page; } public void setPage(String page) { this.page = page; } }
|
效果图:
写在最后
在这里我们还可以是使用RxCache来对数据进行缓存,比如分类可以永久缓存到本地,以节省网络资源的浪费。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| * 获取闲读分类信息 * 永久 * @param oRepos 缓存数据 * @param userName * @param evictDynamicKey false使用缓存 true 加载数据不使用缓存 * @return 数据 */ Observable<Reply<List<ReadTypeBean>>> getTypeList(Observable<List<ReadTypeBean>> repos, DynamicKey userName, EvictDynamicKey evictDynamicKey); * 获取闲读分类下对应类别 * 缓存时间 1天 * @param oRepos 缓存数据 * @param userName * @param evictDynamicKey false使用缓存 true 加载数据不使用缓存 * @return 数据 */ @LifeCache(duration = 1, timeUnit = TimeUnit.DAYS) Observable<Reply<ReadTypeBean>> getStackTypeList(Observable<ReadTypeBean> repos, DynamicKey userName, EvictDynamicKey evictDynamicKey);
|
部分代码
项目地址请移步Github,欢迎Star,Issues,给予鼓励是继续完善与维护的动力!
祝大家撸码愉快!